Tomorrow.io’s Virtual Sensors revolutionize weather observations and help to close the global sensing gap. To use all that data to actually improve forecasting, we next had to rethink models.
Why? For one thing, traditional Numerical Weather Prediction models weren’t built to handle the novel data Tomorrow.io generates, at the speed we generate it. Typical government NWP models require a computational effort so massive that they run in ponderous cycles: input data for 3-6 hours, then do some supercomputer-level number crunching for a few more hours, then, finally, a forecast. Except that in some ways, it’s a pastcast. At the time of output, data in the cycle can be as much as 8-9 hours old. And because weather is a chaotic system and there are relatively few observations going into hypersensitive equations, small inaccuracies and lags matter a lot.
At Tomorrow.io we liken this to trying to navigate a supertanker through an unknown set of islands and shoals, in thick fog, with ancient instruments and a rudder you can only adjust four times a day. It’s a miracle it works at all.
How much better would it be to get through the same complex, chaotic land – and seascape, with a whole fleet of responsive powerboats, each equipped with unerring radar? That’s what we’re doing with modeling.
Our first model was the Nowcast, and it revolutionized near-term forecasting. Trying to land a plane or pave a road, and need to anticipate rain, snow, and fog? We developed a set of equations with unparalleled speed, accuracy, and detail in the 0-3 hour range, capable of assimilating data from our vast array of sensors in ultra short cadences, with minute-by-minute updates. This addressed an enormous gap in weather prediction services between what industries need – specific, reliable information to drive real-time decisions – and what government-run NWPs can generate: a slow, generalized picture.
The Nowcast’s usefulness brought partnerships with such companies as JetBlue and United Airlines, who’ve found it indispensable for short-term operations at their busiest and most storm-prone hubs. But forecasting the next few hours is very different than forecasting a day or a week ahead (which in turn is very different than trying to predict next winter). Picture a caterpillar: if it’s eating leaves, we can predict a bigger caterpillar. But we can’t, by simple extrapolation, predict the transformation to butterfly–much less the wingflap over Tokyo that will cause a hurricane in New York.
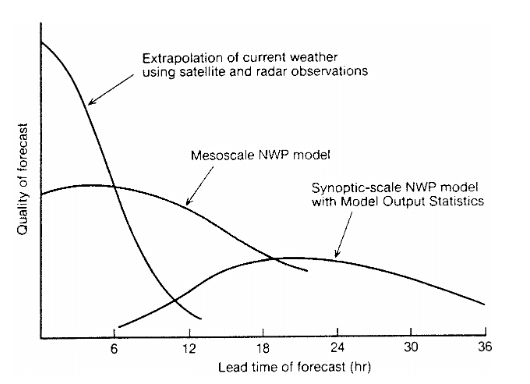
A schematic diagram after Browing (1980) conceptualizing the relationship between forecasting methodology, skill and forecast range.
To model for different time horizons, we needed different science, data, and software architecture. We began by looking at other weather-forecasting companies to figure out why private sector NWPs were still so far from fulfilling their potential. Briefly, there seemed to be two paths. Either you were a giant, like IBM or Panasonic, in which case you built global models that essentially replicate (but claim to outperform) the governmental ones (NOAA’s GFS or the ECMWF Global Model), or you were a small, specialized shop, that focuses on one-off tailored configurations for a handful of niche customers. But here’s the thing: neither of these paths really address the problem.
Trying to compete with the governmental global models was not only a lost battle, we realized, it was the wrong one. The whole point of private market weather companies is to solve problems the governments can’t or won’t solve. Replicating what ECMWF or NOAA spend billions of dollars on building and improving every year, just so you can say you have your own model, doesn’t really make much sense. It’s not about outperforming the government in doing its job, it’s about playing a team game and taking it to the next level.
The small specialized shops we saw often did a decent job in running a specific configuration, but it took them years of work to get there, and months to make even the smallest change.
If forecasts were cars, then you either had a 1908 Ford assembly line – can get you any color Ford as long as it’s black, or you had a backyard garage that can build a more customized car if only you had a year to wait for it.
Neither of these approaches addressed the problems we set out to solve: the developed world would still be stuck relying on one-size-fits-all models for 99% of its weather decisions, and the developing world would be stuck with hardly anything at all.
Enter CBAM.
CBAM stands for Tomorrow.io’s Bespoke Atmospheric Model (or the name we prefer – Tomorrow.io Bad Ass Model) and introduces two major differences. CBAM is microscale, and it’s on-demand.
Let’s start with the microscale piece. Contrast CBAM to the best available public model out there, NOAA’s High-Resolution Rapid Refresh or HRRR, that covers the continental U.S. (“CONUS”). Compared to HRRR.
CBAM can run at much higher spatial resolution. The HRRR boasts of 3km resolution. Global models run at 9-25Km. CBAM can run at resolutions of only tens of meters. That’s the result of better data (coming from our virtual sensors), but also the fact that if you run a model for a smaller domain than the entire continental U.S., you can tune it up to run on a much finer grid, without getting into the “impossible” range in terms of what computers are capable of. Such high resolution allows taking terrain and buildings into account and seeing otherwise invisible phenomena like wind turbulence around them.
Here’s the difference between what CBAM sees and what HRRR gropes through:

Wind vectors as captured by HRRR vs. CBAM tuned for 500m resolution.
As can be seen in the images above, while HRRR’s wind vectors may seem dense, they are in fact quite coarse, and as a result not that accurate. They don’t take into account the fine-scale terrain, which has enormous impacts on airflow at low altitudes. So the wind vectors in the HRRR model are flowing straight, even around mountains, while the those in CBAM depict real-world turbulence and other impacts much more accurately. Think of what that difference means for wind-farm owners, or for pilots.
CBAM can run at much higher temporal resolution. HRRR is updated hourly (with top-ups every 15 minutes). That is, a new simulation is initiated every hour and everything that happens in between each simulation is more or less averaged into one input. Among traditional NWPs, HRRR is considered fast (hence the “rapid refresh” in its name). GFS and ECMWF run only every 4-6 hours. CBAM’s cadences are as fast as minutes.
CBAM assimilates much more data, much more frequently. HRRR is ingesting an already astounding amount of data that NOAA collects, from radars to airplane sensors to buoys in the ocean, and it does it at its hourly clock cycle. We use all that data as a baseline, but then add millions of new data points from things like terrestrial microwaves and vehicles, some of which are being collected every single minute.
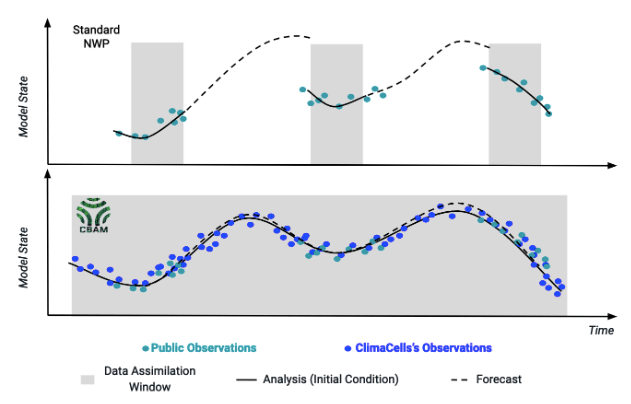
And here’s how it plays out in terms of forecasting. At the top of the chart above, you see a standard NWP model with its usual cycle playing out. Notice the gaps in assimilation of data, where over assimilation time (gray shadow) an hours-old forecast remains in place, while new observations are slowly assembled. This leads to a ‘jump’ between forecasts, where conditions seem to suddenly appear different. To put it another way: that’s the supertanker hitting a small island, that it had no idea existed. The bottom chart blue line is our CBAM model. Our ability to assimilate data more rapidly (and the greater amount and kinds of data we have access to) leads to a smooth curve. There’s no jump: the new conditions emerge as on a clear day and our forecasts have less time to drift from reality.
So how does all this work in the real world? Below is a chart demonstrating exactly that. In red is HRRR, the U.S. national standard, forecasting windspeed 36 hours ahead of time. In green is CBAM predicting the same thing. And in dotted blue line is the actually observed windspeed data. CBAM predicted the real world–and if you’ll notice, predicted it with far better accuracy and temporal resolution. Where HRRR blasts a foghorn, squints, and guesses, our model sees.
CBAM vs. HRRR: 36h wind forecast
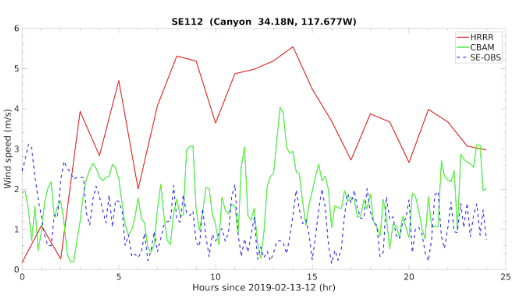
WInd speed comparison between HRRR (red), CBAM (green), and observation (blue) for Feb 13th 2019. The Root Mean Square Error (in m/s) was: CBAM=1.16 vs. HRRR=2.96 (~60% improvement).
Figure: WInd speed comparison between HRRR (red), CBAM (green), and observation (blue) for Feb 13th 2019. The Root Mean Square Error (in m/s) was: CBAM=1.16 vs. HRRR=2.96 (~60% improvement).
And again, remember that HRRR only covers the continental United States. So the vast majority of the world’s population doesn’t even have access to this. They will, however, have access to CBAM, which incorporates the great global models as a starting point and then benefits from the troves of proprietary observations that we’re so obsessed with collecting.
That takes us to CBAM’s other advantage: being on-demand.
The problem with traditional NWP models is not just that they’re a supertanker, better fit for a vast open lane with fair winds. It’s that not everyone who needs weather forecasts is going in the same direction, or steering the same kind of vessel. Tomorrow.io’s model is built for cloudy, swirling, chaotic conditions where different users drive different boats, and need forecasts of different parts of the world. We generate just such forecasts, resolving in minutes, and to an accuracy of meters, conditions that real clients really need. If you’re operating a fleet of autonomous vehicles, launching planes in the air, pouring asphalt on the ground, mitigating flood risks, cultivating despite drought, or timing the resumption of play in a Red Sox-Yankees nailbiter, we can run a model just for you.
In other words, where others give you just that same black Ford Model T–wrapped or ‘post-processed’, perhaps, with a colored bow—we give you the vehicle you need, with a V12 turbo engine, built to order, and we deliver it quickly.
Virtual sensing. Nowcast. CBAM. Our approach is to think outside the box, and to address every link of the chain -observations, modelling, and dissemination–to solve the most stubborn problems in weather prediction.